General Value Functions
A research project exploring general value functions in reinforcement learning for prosthetic control.
Adaptive Switching
Using powered prosthetic hands is challenging for people with limb differences due to the difference between the many possible grasp patterns a device can support, and the limited number of control channels provided by the human body of someone who has lost a limb which can be seen below.
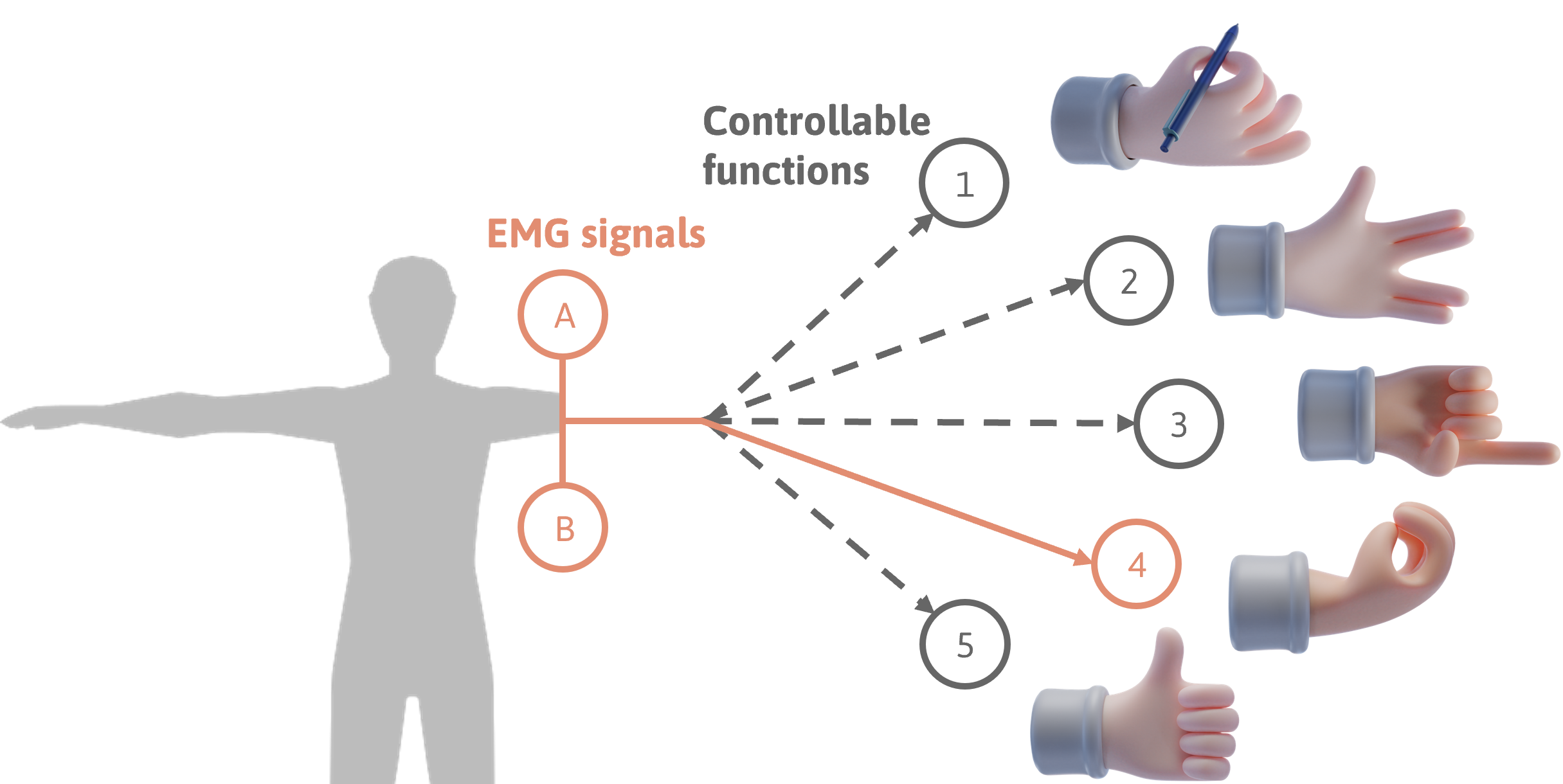
Previous work introduced a machine learning technique called adaptive switching that demonstrated how a robotic prosthesis could learn to predict the functions a user would use, and continually optimize the user’s control interface using this learned predictive information. To get a better idea of how adaptive switching works, imagine all the apps on your smart phone were in a fixed alphabetical list. In order to access an app that starts with Z, you would you have to cycle through all the apps one by one to reach it. Adaptive switching takes the context of how you use your apps and dynamically reorders the list, presenting you with the one you may most likely use next at the top.
Adaptive switching has, to date, only been tested on a desk-mounted arm prosthesis involving simple open/close hand movement, and has not been extended to grasp selection on a prosthetic hand. This project contributes a first look at how the foundation of adaptive switching can be extended to support grasp selection on a sensorized multi-articulated prosthetic hand with multiple grip patterns. Specifically, we show how a cohort of generalized value functions, learned in real time via processes of temporal-difference learning, can predict the future activity of individual fingers in a robotic hand.
General Value Functions
Adaptive switching leverages foundational concepts from the field of reinforcement learning (RL), specifically general value functions (GVFs). GVFs build up predictions about any signal of interest. The GVF’s prediction question is governed by three parameters:
- the signal of interest or cumulant (C)
- the policy (π), which defines the agent’s behaviour while making the prediction
- the discount factor, (0 ≤ γ ≤ 1), which determines how far into the future the prediction spans. For instance, a discount factor of 0.9 represents a prediction horizon of 1/(1-γ) = 10 time steps.
For example, if the question for the agent is “When will the user flex the prosthetic device’s finger?”, the cumulant would be a signal that turns on whenever the finger is flexing. As the finger repeatedly moves over time, the prediction of this signal would increase before the finger moves.
The return, or sum of future signals, can be seen in the equation below. In other words, the return represents an expectation of how signals will accumulate in the future. In short, GVFs allow us to define the prediction problem by posing a question about the environment.
Temporal Difference Learning
Now we have a way to express predictions, there needs to be a way to learn about them. Another component of RL is the learning algorithm. Temporal-difference (TD) learning algorithms allow the agent to learn from experiences as they happen in real-time. It updates the agent’s value function based on experiences as they occur. For instance, if you want to predict the weather for Wednesday, you would have a good prediction knowing Tuesday’s weather without waiting for Wednesday to come.
TD() is a type of TD learning algorithm which uses a trace decay parameter . This parameter determines how past states affect the current state. When , the algorithm takes into account all cumulants in the past while when , it uses only the most recent cumulant to update the value function.
Three essential equations for the TD(λ) algorithm are the temporal difference error (), eligibility traces (), and weight vector update () equations. These can be seen in the equations below. The predicted return, or the prediction of the signal of interest, is the last term of the first equation: . If the model learns well, this value should slowly approach the true return value mentioned previously.
In addition to question parameters, there are answer parameters which can change how the agent answers the GVF question. This includes the learning rate (), the trace decay parameters (), and the function that we can use to construct the state or environment (). Adjusting these parameters, including , can change how the algorithm learns, whether it be speed, how far it looks into the future, or how far it looks into the past.
By combining TD() and GVFs, the system can ask questions about the user’s behaviour and learn to answer them in real-time, providing adaptive control for the prosthetic device.
The Horde Architecture
Modern multi-articulating prosthetic hands have many signals from the motors, the user, and sensors. Since GVFs can only build predictions of one signal of interest, we employ the Horde architecture. This is an RL framework that lets multiple GVF agents, or “demons”, learn and maintain predictions simultaneously. Each GVF has a cumulant, discount factor, and policy while sharing the same state space. For adaptive switching in a prosthetic hand, each GVF learner is assigned to a specific grasp pattern, allowing the system to make independent predictions of each one. By sharing a state space, the GVF learners collectively inform the device’s decisions.
Materials Used
I used the HANDi Hand as an experimental platform to demonstrate real-time learning. The HANDi Hand uses six Dynamixel XL330-M288-T servo motors which can send real-time data such as its position, velocity, temperature, and more. Communication between the computer and the motors was established using the Dynamixel Software Development Kit (SDK). Position and velocity of each motor were chosen to represent the system’s state space. This state space was discretized using a simple binned implementation of tile coding, reducing computational complexity, which is important in real-time continual learning. Each motor produced a flattened one-hot encoding of length 900 of its position and velocity values, which when concatenated across motors, resulted in a single vector representation x(S) of length 5400 with six active bits. Representing the state in this manner clarifies how changes in the motors’ position and velocity influence the predictions, while also preserving the connection between these two properties.
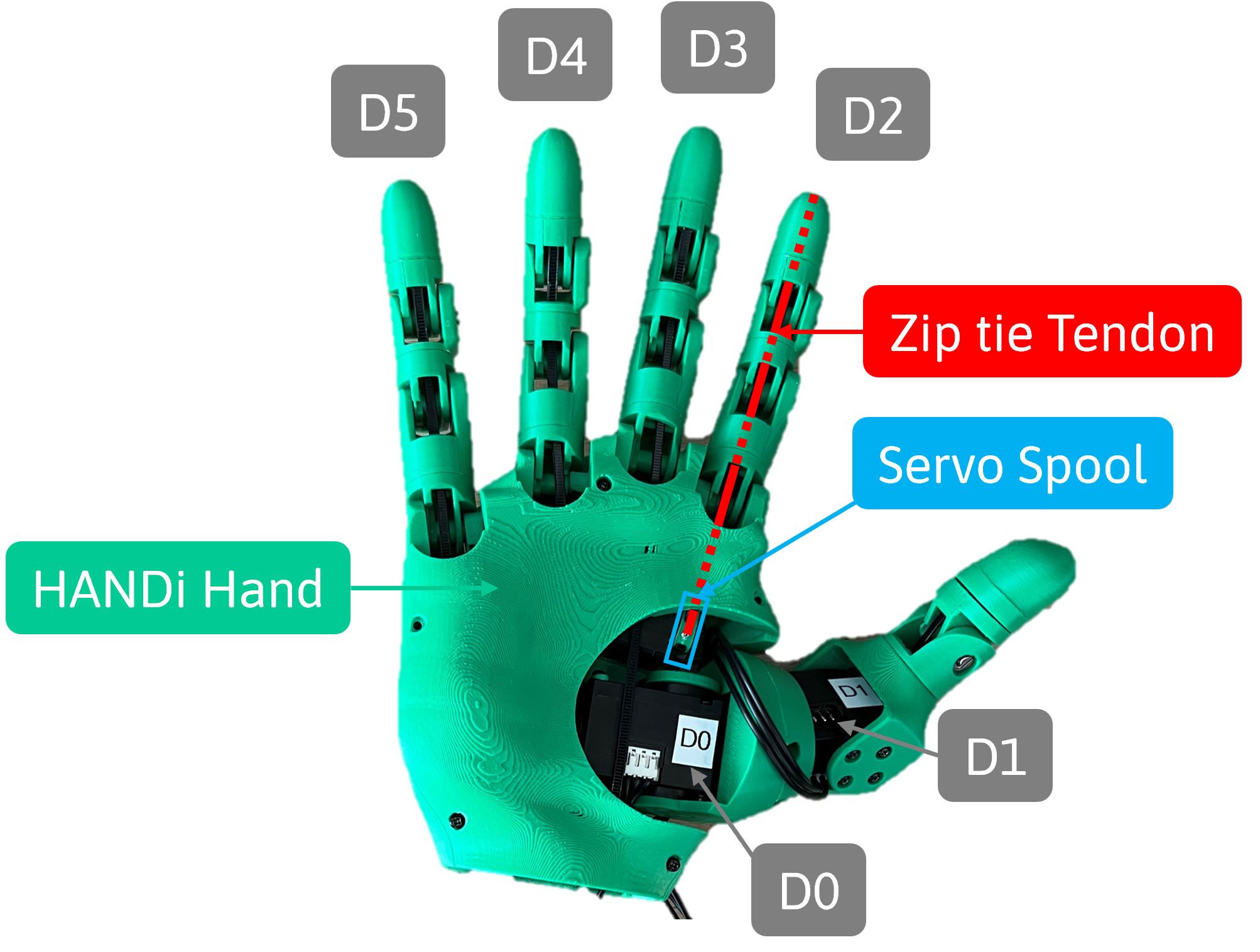
Experimental Setup
We conducted a basic experiment to demonstrate the foundations for adaptive grasp switching, wherein grasping was defined in terms of individual finger movements. A single GVF was assigned to each finger joint motor, posing the computational question: “how much flexion will a given finger motor demonstrate in the near future?” From these predictions, we aimed to determine which finger would be most likely to move next, a precursor to predicting which grasp type a user may need. The behaviour policy () was effected as a sequential movement consisting of each finger closing and opening, one after the other in a cascade, and repeated for 3000 time steps (approximately 380s of real time). This allowed each finger to experience motion approximately 30 times. The cumulant () of each GVF was straightforward, being the flexion of a finger motor in terms of its positional encoding, normalized to values between 0 and 1.
The discount factor () was set to an empirically selected constant value of 0.9 and the trace decay parameter () was set to 0.9. In total, 30 trials were run. The question and answer components of a single finger’s GVF are summarized in the table below:
| Parameter | Value |
|---|---|
| Moving between max/min position | |
| Position of motor | |
| 0.9 |
| Parameter | Value |
|---|---|
| 0.05 | |
| {position, velocity} | |
| 0.9 |
Results and Discussion
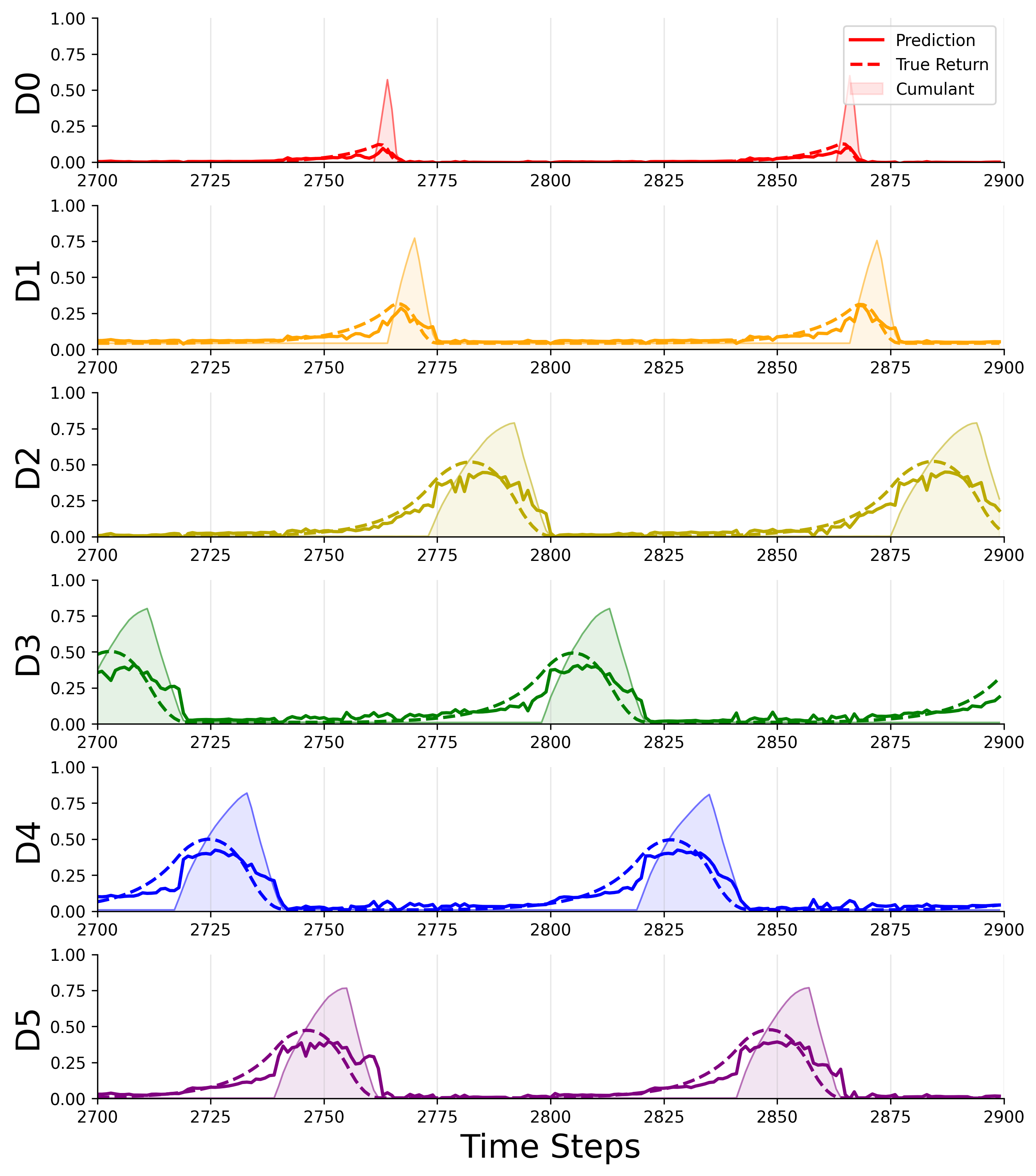
The left figure shows a representative plot of each finger motor prediction value (D0—D5) at the end of learning. The solid lines show the normalized prediction strength of each motor, whereas the dotted lines show the normalized true return values, computed post hoc. The GVF’s cumulant, the motor’s position, can be seen in the shaded regions. True returns and predictions are normalized by timescale () to allow easier visual comparison between predictions and cumulants. The prediction strength positively correlates with the cumulant, suggesting that the horde of GVFs captures the dynamic behaviour of the hand during movement transitions from finger to finger. This behaviour is consistent over many grasp cycles, and independent trials, indicating that learning is reliable and stable as the hand is used. Finally, the predictions can capture the difference between active and inactive states, confirming that the chosen state representation effectively separates different phases of movement. One key finding was that the system could learn how to anticipate movement before sensing motor activity. At the end of learning, predictions accumulated well before the finger moved. This suggests that, with time, the system could be extended to learn patterns of user activity whether it be individual finger movement or grasp patterns.
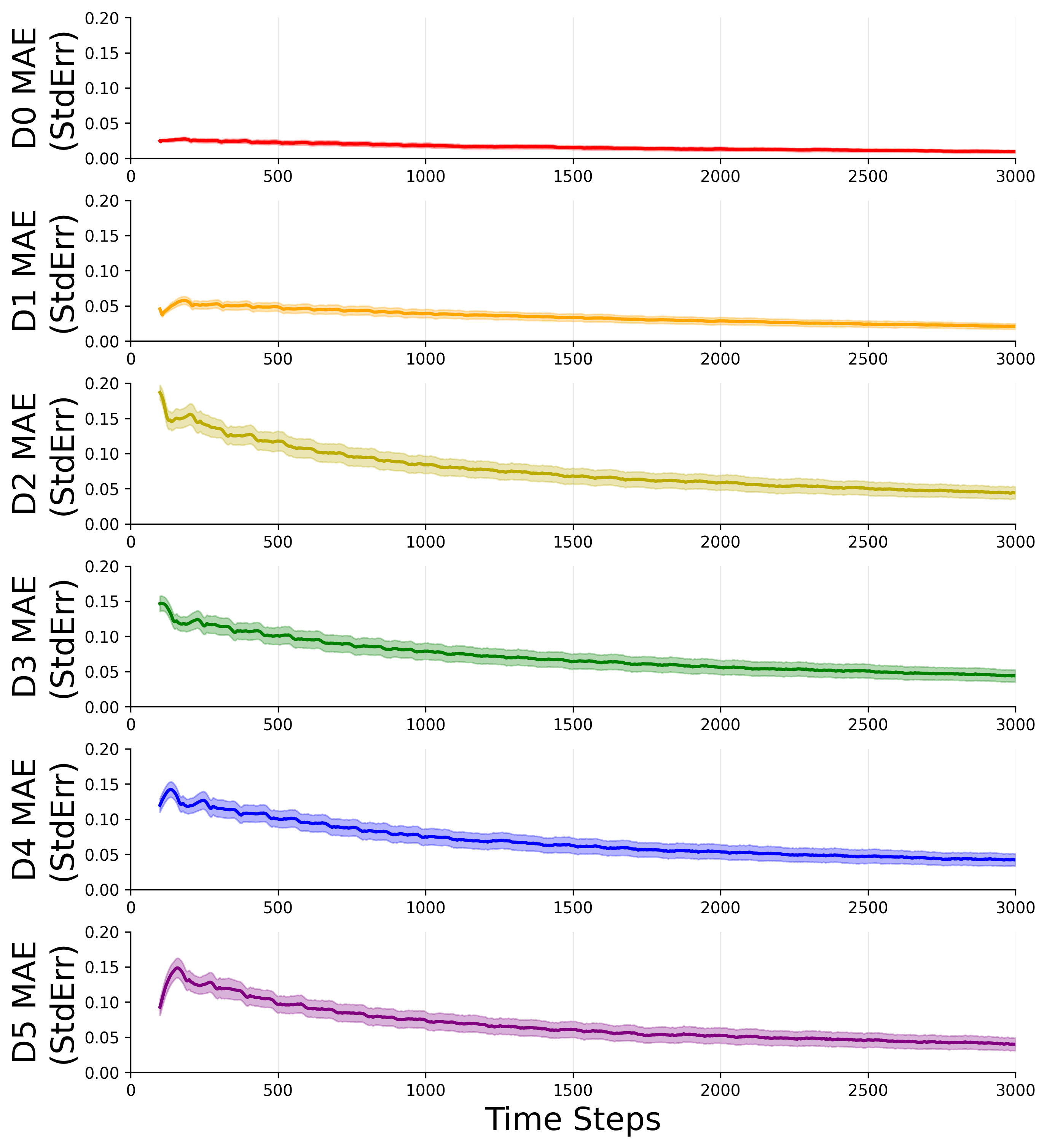
The right figure shows the decrease in mean absolute prediction error (MAE) over 30 experimental trials, with shaded regions indicating the standard error of the mean.
These findings are important for two reasons. First, these preliminary results indicate that adaptive switching can likely be extended from the setting of larger limb movements to predicting the configuration and smaller movements of individual fingers. Imagine, for instance, a user rapidly switching between appropriate finger chord patterns when playing a piano, then voluntarily contacting their muscles to modulate hand shape as they play. Second, our results show that finger movement prediction can approximate the true return when incorporating just motor position and velocity state information. This is promising, as extending the system’s state space with sampled biosingals, inertial measurement sensor data, fingertip force sensors, finger joint angle sensors, and other early indicators of context and use, can likely allow a full transition from desk-mounted adaptive switching to mobile cases where the device is affixed to the human body during tasks of daily living, i.e., real world prosthesis use. Based on the findings herein, our team is now extending the present study to complex grasp patterns that involve simultaneous multi-finger actuation with contextual tasks, advanced state representations, and user-in-the-loop control.
Conclusion
The use of GVFs to predict motor behaviour in prosthetic hands showcases the potential for using AI techniques in assistive rehabilitation technologies intended to support humans in their day-to-day activities. It is a straightforward, yet concrete, example of aligning AI systems to human behaviour and goals. In this work we contributed new preliminary evidence that continually learned GVFs can form accurate predictions of the sequential movement of fingers of a prosthetic hand. This work serves as a foundation for translating previous adaptive switching algorithms to a dexterous manipulation setting, and eventually to real-world contextual prosthesis use.
Further, in sharing early findings on a new variant of the open-source HANDi Hand robotic platform, this work contributes further insight and awareness on environments for real-world AI studies that may be of use to other researchers outside the domain of biomedical robotics. Taken as a whole, this study and the findings presented here add to the body of evidence on how machine learning methods can be deployed in a continual learning setting during interactions with human users, and advance our ability to create assistive technologies, like prosthetics hands, that can operate less like conventional tools and more like intelligence partners in achieving our goals.